Acelerador GBDT
Los árboles de decisión son una técnica de aprendizaje automático ligera y eficiente que ha demostrado su eficacia en varios problemas de clasificación. En el contexto de los sistemas embebidos, la eficiencia energética es tan importante como la precisión, por lo que es necesario buscar algoritmos eficientes que puedan ser acelerados. Esto convierte a los árboles de decisión en un objetivo perfecto para desarrollar un acelerador FPGA. Un solo árbol de decisión no suele ser muy preciso para tareas complicadas pero gracias a técnicas que combinan varios árboles es posible hacer frente a problemas complejos.
Gradiant Boosting Decision Trees
A pesar de sus ventajas, los árboles de decisión individuales suelen carecer de precisión para tareas complejas, por lo que se utilizan métodos de conjunto como Gradient Boosting Decision Tree(GBDT) para mejorar el rendimiento. GBDT entrena árboles secuencialmente, corrigiendo errores anteriores para refinar las predicciones. Los diseñadores pueden equilibrar la precisión, el cálculo y el tamaño del modelo ajustando el número de árboles utilizados, sin necesidad de volver a entrenarlos. Esta flexibilidad es especialmente valiosa en sistemas integrados, donde la memoria y la potencia son limitadas. Además, los árboles de decisión se basan principalmente en comparaciones de enteros en lugar de operaciones de coma flotante, lo que reduce la carga computacional y permite la ejecución en hardware sin unidades de coma flotante.
Las implementaciones convencionales de GBDT sufren de escasa escalabilidad para grandes conjuntos de datos o un gran número de características, pero recientemente algunas implementaciones eficientes han superado este inconveniente. Por ejemplo, LightGBM es un marco de código abierto basado en GBDT muy eficiente que ofrece un rendimiento hasta 20 veces superior al de GBDT convencional. Nuestro acelerador es capaz de ejecutar modelos GBDT entrenados con LightGBM.
Diseño hardware
LightGBM sigue una estrategia uno contra todos para problemas de clasificación que consiste en entrenar un estimador diferente (es decir, un conjunto de árboles) para cada clase, donde cada estimador predice la probabilidad de pertenecer a esa clase. Así, durante la inferencia, cada clase es independiente de las demás, y los árboles de cada clase pueden analizarse en paralelo. Aprovechamos este paralelismo incluyendo un módulo dedicado a cada clase.
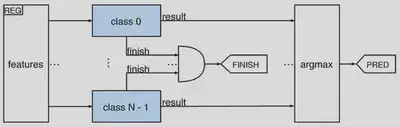
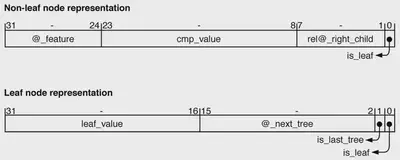
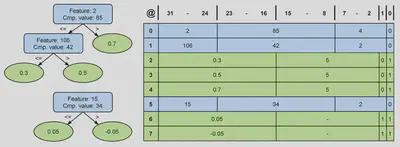
Uno de los objetivos era almacenar los árboles en los recursos de memoria en chip de la FPGA para minimizar las transferencias de datos con la memoria externa. Para lograrlo, los árboles de una clase se almacenan en una memoria RAM dedicada denominada trees_nodes, utilizando un formato compacto de 32 bits para cada nodo. Los nodos que no son hojas almacenan un campo de 8 bits para la característica de entrada, un campo de 16 bits para el valor de comparación y una dirección relativa de 7 bits para el hijo derecho, mientras que el hijo izquierdo se determina implícitamente mediante un recorrido de preorden. Una bandera en el bit menos significativo indica si el nodo es una hoja. Esta estructura optimiza el almacenamiento al evitar las direcciones absolutas, limitando la profundidad del árbol a 128, que es suficiente para los modelos GBDT.
Los nodos hoja utilizan la palabra de 32 bits para almacenar una salida en coma fija de 16 bits, una dirección de 14 bits para el siguiente árbol y dos bits de bandera para indicar si el nodo es una hoja y si es el último árbol de la clase. La representación en coma fija ofrece una precisión similar a la de la salida original en coma flotante de 32 bits, al tiempo que reduce los requisitos de memoria.
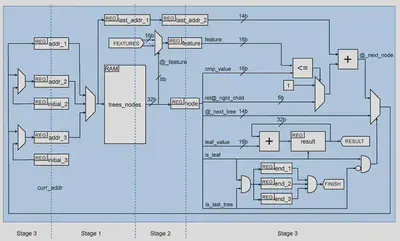
El otro objetivo era mejorar la velocidad, intentando mantener el procesamiento de un nodo por ciclo. Para reducir el ciclo de reloj hemos diseñado una implementación multiciclo. El diseño final ejecuta un nodo en tres ciclos, consiguiendo una importante reducción del periodo de reloj y, al mismo tiempo, proporcionando una arquitectura clara. El problema de este esquema es que no conocemos el siguiente nodo hasta que el anterior ha terminado su etapa de ejecución. Por tanto, no podemos buscarlo con antelación. Por lo tanto, una tubería simple no proporcionará ninguna ventaja. Los procesadores de alto rendimiento alivian este problema incluyendo un complejo soporte para la ejecución especulativa, pero no es una solución eficiente para los sistemas embebidos, ya que introduce importantes sobrecargas de energía.
Sin embargo, este problema puede resolverse combinando el pipeline con un enfoque multithreading. La idea es incluir soporte para intercalar la ejecución de tres árboles diferentes. Esto puede hacerse incluyendo tres registros @_last_node (que es lo mismo que tener tres contadores de programa en un procesador). Los árboles de una clase se dividen en tres conjuntos, y cada contador gestiona la ejecución de uno de estos conjuntos.
Resultados experimentales
Para evaluar el rendimiento de nuestro diseño, hemos ejecutado la inferencia de diferentes modelos en una CPU de alto rendimiento (HP), una CPU Intel(R) Core(TM) i58400 @ 2.80GHz, y también en una CPU de sistema embebido (ES), la Dualcore ARM CortexA9 @ 667 MHz, con los siguientes resultados:
- La CPU HP consume x72 energía, nuestro diseño es x2 más rápido.
- La CPU ES consume x23 energía, nuestro diseño es x30 más rápido.