GBDT Accelerator
Decision trees are a light and efficient machine learning technique that has proved their effectiveness in several classification problems. In the context of embedded systems, energy efficiency is as important as accuracy, so it is necessary to search for efficient algorithms liable to be accelerated. This makes the decision trees a perfect target for developing an FPGA accelerator. A single decision tree is frequently not very accurate for complicated tasks but, thanks to ensemble methods, it is possible to combine several trees in order to deal with complex problems.
Gradiant Boosting Decision Trees
Despite their advantages, individual Decision Trees
often lack accuracy for complex tasks, so ensemble
methods like Gradient Boosting (GBDT) are used
to improve performance. GBDT trains trees
sequentially, correcting previous errors to refine
predictions. Designers can balance accuracy,
computation, and model size by adjusting the
number of trees used, without retraining. This
flexibility is particularly valuable in embedded
systems, where memory and power are limited.
Additionally, Decision Trees rely mainly on integer
comparisons rather than floatingpoint operations,
reducing computational load and allowing
execution on hardware without floatingpoint units.
Conventional implementations of GBDT suffer
from poor scalability for large datasets or a large
number of features, but recently some efficient
implementations have overcome this drawback.
For instance, LightGBM is a highly efficient open
source GBDT based framework that offers up to 20
times higher performance over conventional
GBDT. Our accelerator is capable of executing
GBDT models trained with LightGBM.
Design Architecture
LightGBM follows a onevsall strategy for classification problems that consists of training a different estimator (i.e., a set of trees) for each class, where each estimator predicts the probability of belonging to that class. Hence, during inference, each class is independent of the others, and the trees of each class can be analyzed in parallel. We take advantage of this parallelism by including one dedicated module for each class.
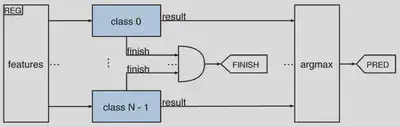
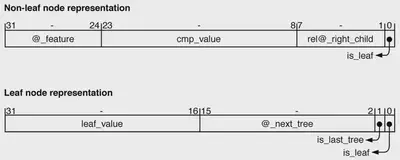
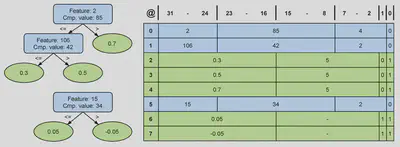
One goal was to store the trees in the onchip memory resources of the FPGA to minimize data transfers with the external memory. To achieve this, the trees of a class are stored in a dedicated RAM memory called trees_nodes, using a compact 32bit format for each node. Nonleaf nodes store an 8bit field for the input feature, a 16bit field for the comparison value, and a 7bit relative address for the right child, while the left child is implicitly determined using preorder traversal. A flag in the least significant bit indicates whether the node is a leaf. This structure optimizes storage by avoiding absolute addresses, limiting tree depth to 128, which is sufficient for GBDT models.
Leaf nodes use the 32bit word to store a 16bit fixedpoint output, a 14bit address for the next tree, and two flag bits to indicate if the node is a leaf and if it is the last tree in the class. The fixed point representation provides similar accuracy to the original 32bit floatingpoint output while reducing memory requirements.
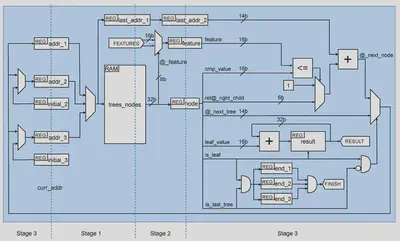
The other goal was to improve the speed, while
trying to keep processing one node per cycle. To
reduce the clock cycle we have designed a multi
cycle implementation. The final design executes a
node in three cycles, achieving an important clock
period reduction and, at the same time, providing a
clear architecture.
The issue with this scheme is that we do not know
the next node until the previous node has finished
its execution stage. Hence we cannot fetch it in
advance. Therefore, a simple pipeline will not
provide any benefit. Highperformance processors
alleviate this problem by including complex
support for speculative execution, but it is not an
efficient solution for embedded systems, since it
introduces significant energy overheads.
However, this problem can be solved by combining
the pipeline with a multithreading approach. The
idea is to include support to interleave the
execution of three different trees. This can be done
by including three @_last_node registers (that is
the same as having three program counters in a
processor). The trees in a class are divided into
three sets, and each counter manages the execution
of one of these sets.
Experimental results
In order to evaluate the performance of our design, we have
executed the inference of different models in a high
performance (HP) CPU, an Intel(R) Core(TM) i58400 CPU
@ 2.80GHz, and also in an embedded system (ES) CPU, the
Dualcore ARM CortexA9 @ 667 MHz, with the following
results:
- HP CPU consumes x72 energy, our design is x2 faster.
- ES CPU consumes x23 energy, our design is x30 faster.